주말 내내 코딩이 너무 하기 싫어서 반쯤 놀아댄 결과 별로 공부한 내용이 없다. 그러다 최근 글을 봤는데 글을 무슨 쓰다 말았어서 OTL... 못 쓴 내용까지 복습하면서 다 정리할 것.
(※ 개인 정리를 위한 것이므로, 이해한 내용 생략다수 + 불친절함 주의)
소멸자 (Destructor)
소멸자란 대충 생성자와 반대의 작업을 수행하는 함수라고 볼 수 있겠다. 그렇기에 생성자가 객체를 생성하는 데 사용되는 함수라면, 소멸자는 객체가 소멸될 때 호출되는 함수이다. 소멸자가 필요한 이유는 다음과 같다.
#include <iostream>
#include <string.h>
class Test
{
int num;
char * word;
public:
Test(int n, char * name);
};
Test::Test(int n, char * name)
{
std::cout << "생성자 실행" << std::endl;
num = n;
word = new char [strlen(name) + 1];
strcpy(word, name);
}
int main() {
Test t(10, "test_instance");
}위와 같은 코드를 살펴 보면, word에 name을 통해 문자열을 넣어주는 과정에서 word를 동적으로 생성하는 과정을 거치고 있다. new 를 통해 동적으로 생성된 변수는 delete를 통해 해제해주어야 메모리 공간을 차지하지 않을 수 있는데, 위 코드에는 그 어느 부분에도 delete를 통해 word를 해제해주는 과정이 존재하지 않는다. 따라서 위의 코드는 동적 생성된 word가 해제되지 못한 채 메모리 공간을 잡아먹는 불상사가 생길 수도 있는 것이다(이를 Memory Leak라고 칭한다). 이러한 일을 방지하기 위해, C++에서는 객체의 소멸 시 생성자처럼 자동으로 실행되는 함수를 지원하는데 이를 '소멸자'라고 한다.
소멸자는 그 형식이 매우 간단하다. 객체를 생성한다는 역할을 갖고 있기에 객체의 생성에 필요한 인자를 다양하게 전달받을 수 있었던(즉, 오버로딩이 가능했던) 생성자와는 달리, 소멸자는 객체의 삭제라는 역할 때문에 별다른 인자를 필요로 하지 않는다. 따라서 오버로딩 또한 불필요하고 애초에 되지도 않는다. 소멸자를 코드 내에서 만드는 방법은 아래와 같다.
#include <iostream>
#include <string.h>
class Test
{
int num;
char * word;
public:
Test(int n, char * name); //생성자
~Test(); //소멸자
};
Test::Test(int n, char * name)
{
std::cout << "생성자 실행" << std::endl;
num = n;
word = new char [strlen(name) + 1];
strcpy(word, name);
}
Test::~Test()
{
std::cout << "소멸자 실행" << std::endl;
delete [] word;
}
int main() {
Test t(10, "test_instance");
return 0;
}소멸자는 인자를 갖지 않는 생성자의 맨 앞에 '~'를 하나 붙여 사용한다. 예시 코드 속 소멸자는 동적으로 생성된 word를 delete로 해제하여 메모리 누수를 일으키지 않도록 조치하고 있다. 위 코드를 돌려보면 다음과 같은 결과가 나온다.

main 함수에서 선언한 Test의 인스턴스 t가 생성되며 생성자가 실행되고, main 함수가 종료되며 자동으로 소멸자가 실행되는 것을 확인할 수 있다. 이로써 소멸자는 객체가 파괴될 때 자동적으로 호출된다는 사실 또한 확인할 수 있다. 참 영리하고 편하다.
생성자에 디폴트 생성자가 존재했던 것처럼, 소멸자에도 그와 똑같은 '디폴트 소멸자'가 존재한다. 생성자 때와 마찬가지로 프로그래머가 소멸자를 아무것도 정의하지 않는다면 디폴트 소멸자가 수행될 것이다.
복사 생성자
이름 그대로 객체를 '복사해서 생성'한다는 의미의 생성자이다. 이미 만들어져 있는 인스턴스를 복사해서 여러 개로 복사한다는 것이다. 복사를 하기 위해선? 복사를 할 대상인 원본 데이터에 대한 정보가 필요할 것이다. 그렇기에 복사 생성자는 대부분 복사할 '원본 인스턴스'를 인자로 받아서 인스턴스를 생성한다.
#include <iostream>
#include <string.h>
class Test
{
int num;
int num2;
public:
Test(int n1, int n2); //생성자
Test(const Test& t); //복사 생성자
};
Test::Test(int n1, int n2)
{
std::cout << "생성자 실행" << std::endl;
num = n1;
num2 = n2;
}
//복사 생성자
Test::Test(const Test& t)
{
std::cout << "복사 생성자 실행" << std::endl;
num = t.num;
num2 = t.num2;
}위의 코드에서는 복사 생성자에서, 복사할 인스턴스의 정보를 받기 위해 Test& 형을 인자로 받고 있다(즉, 레퍼런스로 넘겨 받는다). 원본 인스턴스 t를 const로 받는 이유는 t의 내용을 바꿀 수 없게 하기 위해서(보호하기 위해서)이다. 이는 뒤에서 다룰 const 부분에서 좀 더 자세히 적는다. 여담으로, 굳이 복사 생성자가 아니더라도 특정 함수에서 인자로 받는 변수의 내용을 바꾸지 않을 예정이라면 const를 사용하여 변수를 보호하는 것이 좋다고 한다.
int main() {
Test t1(10, 20);
Test t2(t1); //복사 생성자를 통한 생성
return 0;
}만든 복사 생성자를 사용할 때는 그냥 저렇게 사용하면 된다. 다만, 복사 생성자에 호출에는 알아두어야 할 점이 하나 있는 듯 싶다.
Test t1(10, 20);
Test t2(t1); //복사 생성자를 통한 생성
Test t3 = t2;위 코드의 맨 마지막 줄 같은 경우에도 복사 생성자가 알아서 호출된다는 것이다. 그냥 대입처럼 보이지만 Test 객체인 t3를 새로이 '생성'하면서 대입을 진행하고 있기 때문에 C++ 컴파일러가 알아서 복사 생성자를 호출하게 만드는 것이다. '생성하면서 대입한다' 부분이 중요한 것이므로, 이 상황이 아니면 복사 생성자는 호출되지 않는다.
Test t1(10, 20);
Test t2(t1);
Test t3;
t3 = t2;요컨대 이런 상황이 해당되지 않는다는 것이다. 위 코드는 t3라는 인스턴스를 일단 생성한 후 t2를 대입하는 것이지, 생성하며 대입이 이루어지는 과정이 아니기 때문에 복사 생성자가 호출되지 않는다.
복사 생성자도 '디폴트 복사 생성자'가 존재한다. 디폴트 복사 생성자에서는 클래스 내의 모든 변수들을 알아서 매치시켜 대입함으로써 복사해준다. 똑똑하고 편하다. 이 친구가 만능이었다면 우리가 수고스럽게 복사 생성자를 적어줄 필요가 없었을 터이나 유감스럽게도 그런 편이 아닌가보다.
#include <iostream>
#include <string.h>
class Test
{
int num;
char * word;
public:
Test(int n, const char* name); //생성자
~Test();
//Test(const Test& t); //복사 생성자
};
Test::Test(int n, const char* name)
{
std::cout << "생성자 실행" << std::endl;
num = n;
word = new char[strlen(name) + 1];
strcpy(word, name);
}
Test::~Test()
{
if (word != NULL)
delete[] word;
}
int main() {
Test t1(10, "Hi");
Test t2 = t1;
return 0;
}디폴트 복사 생성자의 편리함을 느끼기 위해 복사 생성자를 따로 작성하지 않고 t1을 복사한 t2 인스턴스를 생성하도록 해보았다. 위의 예시 코드 속 클래스 구성처럼 간단한 정수 변수들로만 구성된 클래스였더라면 별 문제 없이 작동할 테지만 이 클래스에서는 포인터가 포함되어 있기 때문에 문제가 생긴다.
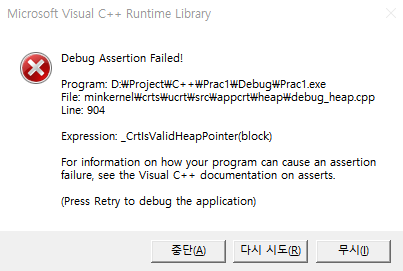
디폴트 복사 생성자는 단순히 클래스 내 변수들을 알아서 매치시켜서 '대입'한다고 하였다. 위의 경우에서는 t1 내의 포인터 변수인 word를 t2가 대입받는 형태로 복사 생성이 이루어질텐데, word가 포인터 변수이기 때문에 결과적으로는 t1과 t2가 서로 같은 값(즉 t1의 word 의 주소)을 갖게 된다는 것이다. 생성이야 별 문제없이 넘어가겠으나 문제는 소멸인데, t1이 먼저 소멸될 경우 t1의 word 또한 없어질 것이고, t2가 가리키던 것은 순식간에 없어진다. 이러한 상황에서 t2를 소멸시킬 차례가 오면, 해제해야 하는 t2의 word는 이미 해제된 상태이기 때문에 오류가 일어나는 것이다. 따라서 이 경우에는, 단순히 변수를 대입하는 것이 아니라 아예 동적 할당을 거쳐야 한다. 이렇게 변수를 대입만 하는 것을 '얕은 복사(Shallow Copy)', 할당을 거쳐 대입하는 것을 '깊은 복사(Deep Copy)'라고 한다. 결국 얕은 복사로는 대입이 제대로 이루어지지 않을 변수가 있다면 깊은 복사를 통해서 복사 생성이 가능하게끔, 프로그래머가 복사 생성자를 따로 작성해주어야 한다.
생성자 초기화 리스트 (Initializer list)
위의 내용 쓰는데 기가 다 빨려서 조금 적게 적어야지.
생성자의 초기화 리스트란, 생성자를 작성할 때 사용자가 생성자에 넣을 인자를 전달하지 않았을 경우 이를 디폴트 값으로 채워주는 역할을 수행한다고 보면 될 것 같다.
#include <iostream>
#include <string.h>
class Test
{
int num;
int num2;
public:
Test(int n1, int n2); //생성자
Test();
};
Test::Test() : num(10), num2(20) {}
Test::Test(int n1, int n2)
{
std::cout << "생성자 실행" << std::endl;
num = n1;
num2 = n2;
}중간 부분의 아무런 인자를 전달받지 않는 생성자를 살펴보면, 함수 이름과 괄호 뒤로 무언가가 나열되는 것을 확인할 수 있다. 이것이 바로 초기화 리스트로, 위 코드에서는 num을 10, num2를 20으로 초기화해주고 있다. 요 부분에서 변수들을 초기화해주기 때문에, 함수의 몸통 부분에서는 별다른 작업을 해줄 필요가 없다. 그렇기에 몸통 부분이 아예 비어있는 것 또한 확인할 수 있다.
재밌는 점은, 초기화 리스트에서 변수 명은 서로 같아도 된다는 점이다. 이게 무슨 말이냐 하면은,
Test::Test(int num, int num2) : num(num), num2(num2) {}
요게 된다는 것이다. 만약 저걸 그대로 함수의 몸통 안에 썼다면 오류가 떴겠지만, 초기화 리스트에서는 괄호 안의 변수를 무조건 생성자의 인자로 여기기 때문에 변수 이름이 같더라도 알아서 구분이 된다.
이렇게 초기화 리스트를 사용하게 되면 그냥 평범하게 생성자를 사용할 때와는 달리, 생성과 초기화가 동시에 이루어지게 된다. 그렇기 때문에 생성과 동시에 초기화가 이루어져야 하는 것들(대표적으로 레퍼런스)을 클래스 변수로 사용하고 싶을 때는 초기화 리스트의 사용이 꼭 필요하다고 한다.
const 함수
앞전에 복사 생성자에서, 어떤 객체를 인자로 받을 경우 해당 인자를 변경할 생각이 없다면 const를 써서 보호하는 것이 좋다는 이야기를 적었었다. const가 함수에서 사용될 경우, 이 함수는 변수의 값을 단순히 '읽기'만 하는 함수가 된다. 이렇게 만들어진 함수를 '상수 함수'라고 칭하는 것 같다.
#include <iostream>
#include <string.h>
class Test
{
int num;
int num2;
public:
Test(int n1, int n2); //생성자
Test();
int showNum() const;
};
Test::Test() : num(10), num2(20) {}
Test::Test(int n1, int n2)
{
std::cout << "생성자 실행" << std::endl;
num = n1;
num2 = n2;
}
int Test::showNum() const
{
return num;
}
int main()
{
Test t1(10, 20);
std::cout << t1.showNum() << std::endl;
return 0;
}간단하게 적용하면 이런 식으로 구성된다. num 값을 반환하는 showNum()함수를 만들었고, 이를 const 함수로 설정하기 위해 함수 이름 뒤에 const를 작성했다.
상수 함수는 주로 private 으로 설정된 변수들(즉, 외부에서의 접근이 불가한 변수)의 값을 반환해주는 함수에 많이 사용되는 것 같다. private 변수를 변경할 가능성도 없으며 보다 편리하게 값을 받는 것이 가능하기에.

